
The Difference Between Artificial Intelligence and Actual Intelligence
Neural networks don't pursue truth, don't possess understanding, and don't apprehend essences.
As an Amazon Associate I earn from qualifying purchases

Almost all of the conversation about artificial intelligence seems to revolve around specific use-cases, as if to say, “A.I. is a tool, and all tools can be used for virtuous or for vicious purposes.” Never mind that this position of tool neutrality has been widely criticized for at least sixty years by authors such as Marshall McLuhan, his student Neil Postman, and most recently, Pope Leo XIV in Magnifica Humanitas. At this point, it seems well established that no technology is ever neutral, but this seems far more obvious when it comes to artificial intelligence. After all, A.I. was developed to mimic human intelligence, which alone should cause us to stop and think deeply about its very nature, not merely its applications. While others will continue to debate the use of A.I. for this or that purpose—for writing assistance, medical research, sharpening one’s thinking, companionship . . . the list goes on—I would like to focus on the much more basic question: how does artificial “intelligence” differ from human intelligence? Of course, this is a big question, too big for one short essay, and it is a subset of the larger question about what it means to be human. Answering the larger question will necessarily involve commentary on the nature of the soul, the soul’s relationship to a body, and a whole host of other theological, metaphysical, and anthropological issues. My purpose here is much more modest: I want to investigate how A.I. differs from the human intellect in three important ways. The human intellect pursues truth, is capable of understanding, and apprehends essences. Artificial intelligence does none of these things.

Before addressing these three differences, it is important to briefly describe the way in which artificial intelligence works. I am unconcerned for the moment about the particular interface that is layered on top of the algorithm. Or, rather, I should say that I am very concerned about the interface, especially as it mimics human interaction, but that this particular essay will not focus on the interface. Instead, I am focused only on the algorithm, or the step-by-step process that starts with input data and ends with output data. The algorithm that underpins artificial intelligence is called a neural network. For our purpose here, we do not need to dive deep into all the ins and outs of how a neural network is built and functions. Rather, there are only two things that we need to know. The first thing is that a neural network does all of its calculations by breaking the input into pieces and building up patterns from those pieces. It takes input, transforms it through many layers of increasing granularity, and then uses learned patterns at the smallest level to predict and utilize patterns at the higher levels, eventually leading to an output. In other words, a neural network works on parts instead of wholes.
The second thing we need to know is that a neural network is probabilistic in nature. The results it produces are not logical certainties, nor are they even intended to be. The results of the neural network are only those that are calculated by the model to be the most likely given a particular input. For example, as ChatGPT produces the next word in its response, it is choosing the output that has the highest probability of following what has come before. Similarly, as Grok is used to generate a picture, it is looking at the most likely pixel coloring in a particular spot given the prompt and the surrounding pixels, and as Gemini is used to transcribe human handwriting, it is analyzing the image and producing the most probable match. Probabilistic behavior is at the very heart of how a neural network functions. However, this is not the only way in which the algorithm is probabilistic. If it were, the algorithm would still be deterministic, meaning that every time we asked it the same prompt, we would get exactly the same answer: the one with the highest calculated probability. We know from experience that this is not true. The answer changes every time we ask for something, even if we ask in exactly the same way. This is because modern neural networks, especially those based on large natural language models, have been programmed to occasionally, and randomly, give an answer that is not the most probable. One reason for this is that early on the researchers realized that a certain amount of randomness led to a product that was more believable on the part of the user. It may also be that this produces more accurate results over time, but that is debated. Regardless, what is not debated is that the neural network is, by design, a probabilistic mechanism.
With that background in place, we are ready to address the three ways in which artificial intelligence is, and always will be, categorically different from human intelligence. First, the human intellect is oriented towards truth. In the Summa Theologica (I.16.1), Aquinas writes, “As the good denotes that towards which the appetite tends, so the true denotes that towards which the intellect tends.” In other words, the mind wants to know true things and know them to be true. I wish this were not a controversial statement. And yet, as beauty and goodness long ago fell under the guillotine of relativism, it seems that truth itself has been tied down and awaiting the wrath of Madame. Given this reluctance on the part of modernity to admit even the obvious, it is worth restating the obvious: objective truth exists, and the human intellect is oriented towards knowing that truth. In fact, the very definition of “truth,” at least according to Aquinas, is “the conformity of the intellect and thing.” To say that the human intellect is oriented towards truth is to, in some way, say that it wants an encounter with something outside of itself, to know something that exists independently of thought, and to conform itself to that reality.
On the other hand, the neural network is in no way oriented towards truth. It is unconcerned with conforming its answers to anything beyond itself except perhaps the persuasion of its interlocutor. It is like trying to exercise the art of rhetoric without the prior art of logic. This comes from its probabilistic nature. To put it bluntly: the neural network is oriented towards the probable, not the true. Whether the algorithm gives a simple answer to a query (When did the Civil War begin?), a full explanation on a topic (Why did the Civil War happen?), or even an ongoing “dialogue” with the human user, its responses are produced by mere probabilities, not an orientation towards truth. This is most evident in the fact that ChatGPT, as of publication time, still misses multiplication problems involving large numbers. This is because it doesn’t actually perform calculations; rather, it finds instead the “most likely” digits that follow the inquiry. The answers are bizarrely close to correct, but often with a random digit or two in the middle being off. What’s more, the incorrect digits that are off will differ every time the query is asked. This is particularly interesting because it could be that mathematics is the last bastion against the aforementioned attack of relativism. Few would argue that the product of two numbers is one exact answer, and yet ChatGPT seems unconcerned about getting this answer correct.
It may be helpful to contrast the neural network with most traditional algorithms, which are the result of performing predictable steps that the programmer knows will always produce the correct result. Think of implementing Euclid’s algorithm for finding the greatest common divisor of two numbers. A truth-oriented human intellect discovered the algorithm, and a programmer makes the computer perform the steps. In cases such as this, the computer is not doing anything fundamentally different than a human being would in running the same algorithm with a paper and a pencil. The case of the neural network is categorically different, for it has no guarantee of outputting the same results every time, let alone true results, and it is not designed to do so. For this reason, it can never be oriented towards the truth—it is always at best oriented towards the probable.
This is not to disregard something like the study of statistics in which the entire discipline is about using probabilities to answer questions. However, in statistics probability is used to answer questions that are probabilistic in nature. Moreover, the very science of statistics is about being exact about the nature of probability. It is that exactness that is truth-oriented, not the probabilities themselves. Something similar can be said about advances in physics suggesting that the nature of reality might be based on probabilities. Even if this is true, the human mind is still oriented towards the exactness of the claim itself. The difference for a neural network is that it is never exact about anything; it operates only through probabilistic answers.
The second way in which artificial intelligence differs from human intelligence is that human intelligence is capable of understanding. The human mind, while capable of running Euclid’s algorithm, can also understand why the results of the algorithm are true. In other words, the human mind is capable of at least two things: algorithm and understanding. What’s more, these two acts of the mind are different from one another. Computer programs, including both traditional ones as well as neural networks, can only do the first thing. This is not mere opinion; it is well-known to computer scientists who refer to algorithms as “Turing computable” and know full well that a computer is only ever capable of Turing computable processes. As for the human intellect, there is an act, which we call “understanding,” that is not Turing computable, and therefore out of reach of computer programs. There are several mathematical arguments for this, including those stemming from the work of Turing himself (the “Halting Problem”) and of Gödel (the “First Incompleteness Theorem”). However, the details of these two arguments are beyond our scope. Instead, to illustrate the point, we rely on an elegant argument from the American philosopher John Searle from nearly one hundred years ago.
Searle imagines being locked in a room with an endless supply of paper and pencils and all of the steps necessary to process information in the same way that a neural network does, but in a language unfamiliar to him. For Searle it was Chinese, which is why this argument has become known as the “Chinese room argument.” The person locked in the room receives a query written in this unfamiliar language through a slot in the door, runs it through the algorithm—the fact that this would take longer than the age of the universe is no matter—and exports the result written in the same unfamiliar language back through the slot. These exchanges continue in the same way that they would on ChatGPT, with the user continuing to ask follow-up questions, and the human calculator responding by performing the tedious calculations outlined by the neural network’s code. In this setup, the person outside the room has the experience that the person inside the room is responding intelligently, with understanding. However, the reality is that the human calculator understands neither the input nor the output, specifically because it is all being done in an unfamiliar language.
Contrast that with someone who does know the language of inquiry and knows the topic being discussed. If the respondent is good enough and the speed is fast enough, the inquirer may not be able to perceive the difference, but there is a difference. More importantly, at least as it concerns our thesis, the same difference is present in our interactions with a neural network such as that underlying ChatGPT.
The genius of Searle’s argument is that it demonstrates clearly that there are at least two things of which the human mind is capable: algorithm and understanding. Yes, we can perform algorithms to produce true answers, as is the case of the person responding in an unknown language. That is decidedly different from understanding the question, the content surrounding the question, and the truth of the correct answer.
Perhaps an example more familiar to most of us is honing a math skill, maybe long division, and being able to correctly apply it but without any idea why it works. In such situations, the human intellect is performing an algorithm without the accompanying act of understanding, again demonstrating that algorithm and understanding are two different things. Algorithms, those based in A.I. or otherwise, are always and forever only algorithms. What Searle demonstrates is that there is something about the human intellect that is decidedly different from the mere application of algorithm: the act of understanding.
I am using the word “understanding” in a more general sense than is typically used by philosophers. Here I mean something like the grasping of the why-is-it of a proposition or even an object. Further distinctions could be made between understanding as the intellectual virtue that allows the human intellect to grasp self-evident principles (Summa I.II.58.4) versus “total comprehension” as the perfect and exhaustive grasp of a proposition or object. I leave these and other distinctions to the philosophers. The salient point for us is that all such acts of the intellect are non-algorithmic, and an algorithm, by definition, can only be algorithmic. As such, a neural network can never grasp first principles, the logic of an argument built upon them, or consequently the totality of the why-is-it of a proposition or object.
The final way in which artificial intelligence differs from human intelligence is that the human intellect is capable of perceiving essences. As we said earlier, the intellect tends towards truth. Aquinas refines this assertion later in the Summa: “The proper object of the human intellect which is united to a body is a quiddity or nature existing in corporeal matter” (I.84.7). When we look at an object, for example, we first apprehend the whole—the what-is-it—and only later concern ourselves with the details. A neural network operates very differently. It first breaks the whole into smaller and smaller pieces and then uses those pieces to make a probabilistic conclusion. We can see this difference clearly in a now well-known example from a 2015 research paper by Goodfellow, Shlens, and Szegedy. In their experiment, they fed the following image into a neural network that was trained to recognize various animals:

The algorithm responded that, with 57.7% confidence, this was a panda. The researches then fed the following image into the same neural network:
This time the algorithm responded with 99.3% confidence that the animal was a gibbon. Of course, when we look at these images, we not only see a panda, but the same panda. How did the algorithm get the second answer not only wrong but wrong with such a high degree of confidence? This happened because the researchers layered in a digital interference pattern in the background that was undetectable to the human eye and designed specifically to fool the neural network. It fooled the neural network precisely because neural networks look at the smallest pieces first and use them to build up patterns that are used in their probabilistic computations.
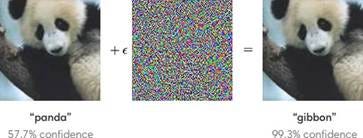
The point is not that the computer got the answer wrong on the second pass. Over time, it may be possible for neural networks to detect these interference patterns and filter them out before making the final prediction. The far more interesting point is that human beings do not make the same mistake. This is because we normally see “wholes” first and worry about details later, and some details are too small for us to detect and do not get in the way of the what-is-it of the thing. Even knowing there is an imperceptible inference pattern in the second image, few human beings would say, “That is not a panda. It is a gibbon.” To be clear, I am not saying that humans don’t perceive details. Neither am I saying that there aren’t times when we look at details to discern a whole, as in the case of diagnosing diseases by looking at blood samples under a microscope or through various blood tests.
What is important for us is that the human mind is capable of perceiving the what-is-it of a thing along with its constituent details, whereas an artificial intelligence only sees details and uses them to make predictions about the whole. Human beings can proceed from the “top down” in the grasping of a thing, whereas neural networks always proceed from the “bottom up.” This does not mean that a neural network is ineffective at naming what a thing is. On the contrary, we all have experience with just how good these algorithms have become at such tasks. The point is only that how it is doing this is decidedly different from the way the human intellect proceeds.
This ability to both see both the what-is of an object along with its constituent details finds a parallel in “The Synthetic Impulse in Catholic life,” in which Bishop Daniel Flores describes the Thomistic distinction between the synthetic act of the mind and the analytic act of the mind:
Thomas himself was familiar with the Greek terms that underlie our words ‘analytical’ and ‘synthetic’, but he preferred the Latin manner of describing these two different ways of using the mind: modus resolutorius and modus compositivus, or the mode of resolution and the mode of composition. The via resolutionis starts with the thing known and reduces it to its constitutive parts. The via compositivus points toward the substance, or thing, in its actual act of existence.
There is a striking resemblance between these two “ways” and the two hemispheres of the human brain as described by the British psychiatrist Iain McGilchrist Such in The Master and His Emissary. McGilchrist is highly critical of the popular notions about “left brain” and “right brain,” and convincingly demonstrates that the two sides of the brain can be best understood as an analytic (left) side seeing things as parts and a synthesizing (right) side seeing things as wholes. However, what McGilchrist uniquely adds to the discussion is that cultures both past and present have often emphasized one of these functions to the detriment of the other. When such an imbalance happens, it not only atrophies the side of the brain being ignored, but it also shapes our view of what intelligence is. McGilchrist points to three moments in human history that have cumulatively contributed to a left-brain (analytic) dominance: the Reformation, the Enlightenment, and Modernism. Consequently, in the present historical moment, not only has right-brain functioning atrophied, but a culture that has increasingly focussed on left-brain activity has also come to think that intelligence is based in left-brain activity.
I bring this up because there is an obvious objection to all three of my arguments: the human intellect in fact does not pursue truth, is not capable of understanding, and does not apprehend essences. Rather, is does exactly what a neural network does: sees patterns in details and uses these patterns to construct something like a “fiction of meaning,” maybe even as an evolved survival mechanism. In this way, there is really no difference between human intelligence and artificial intelligence. Notwithstanding the fact that such an objection fails to address either Searle’s Chinese Room argument or the adversarial examples from Goodfellow, et al—let alone stronger arguments from Turing’s Halting Problem and Gödel’s Incompleteness Theorem, which I have mentioned but not fully discussed—such a view of human intelligence is likely the result of McGilchrist’s observation that culture since the scientific revolution has focussed almost entirely on the left hemisphere of the brain. In other words, since we have a priori ignored the synthesizing (right-side) brain—that part that specifically perceives the what-is of an object—we have weakened its capabilities and have virtually convinced ourselves that it doesn’t exist.
Another way of saying this is that we have redefined human intelligence to match artificial intelligence and subsequently claimed that there is no difference between the two. The identification of one with the other is perhaps all the more convincing because the redefinition occurred long before the advent and widespread rollout of A.I. Moreover, our repeated and long-term interaction with A.I. is likely to reinforce this one-sided view of the human intellect. Per McLuhan and Postman, the use of a technology will form us not merely by its misuse, but also by its mere use. Our interaction with A.I. will continue to shape the way that we think about intelligence itself, and the consequence may be that more and more people will come to define intelligence in terms of how a neural network functions. Nevertheless, the ability of the human intellect to pursue truth, understand that truth, and perceive the what-is of an object has not disappeared altogether. We still instantly recognize a good friend from across the room without examining and analyzing the details of their appearance. Therefore, these three distinctions between human intelligence and artificial intelligence remain, and will perhaps become more important to keep in mind as our interactions with A.I. normalize.
Whatever successes artificial intelligence may have now or in the future—from solving novel mathematics problems, to advancing medical research, or even to creating beautiful music, all of which is not out of the realm of possibility and some of which is already happening—what remains true is that it will do so in a way fundamentally different from human intelligence. Perhaps in the end, a lot of words are expended here on defending the obvious fact that A.I. is not and never will be human. Yet, as A.I. does improve it may start to seem more and more human, especially as we become accustomed to its manner of interaction through our repeated and long-term use. Indeed, especially as robotics catches up with the software, we may find ourselves in a world envisioned by films like Ex Machina. In that case, the distinctions outlined here may end up being increasingly relevant. Although, if and when that happens, perhaps the best advice comes from the Narnian hero, Mr. Beaver: “There’s no two views about things that look like Humans and aren’t.” When encountering such a being, “take my advice … you keep your eyes on it and feel for your hatchet.”1

Jake Tawney is Director of Curriculum and Academic Resources for the Institute for Catholic Liberal Education (ICLE) and author of Another Sort of Mathematics with Encounter Books.
I am very grateful to the two Andrews, well familiar to readers of these pages, for their contributions to these thoughts. Mr. Zwerneman suggested the consideration of the nature of probability in statistics and modern physics, and Mr. Ellison gave me the content from McGilchrist and pushed me to refine the concepts of truth and understanding.